最近意外获取了一个PDF链接(链接已被我和谐掉)。
虽然我不会看这个文档,但是这不影响我生气他们不提供PDF源文件的下载链接。
所以我就试着寻找一些蛛丝马迹来解决这个问题。
类似于我《怎样从网上手扒原图》一文所说,浏览器的开发者工具可以给我们提供一些帮助。
可恶,这帮人竟然把阅读的部分直接封装了一个类。(其实也是常规的防盗操作。)
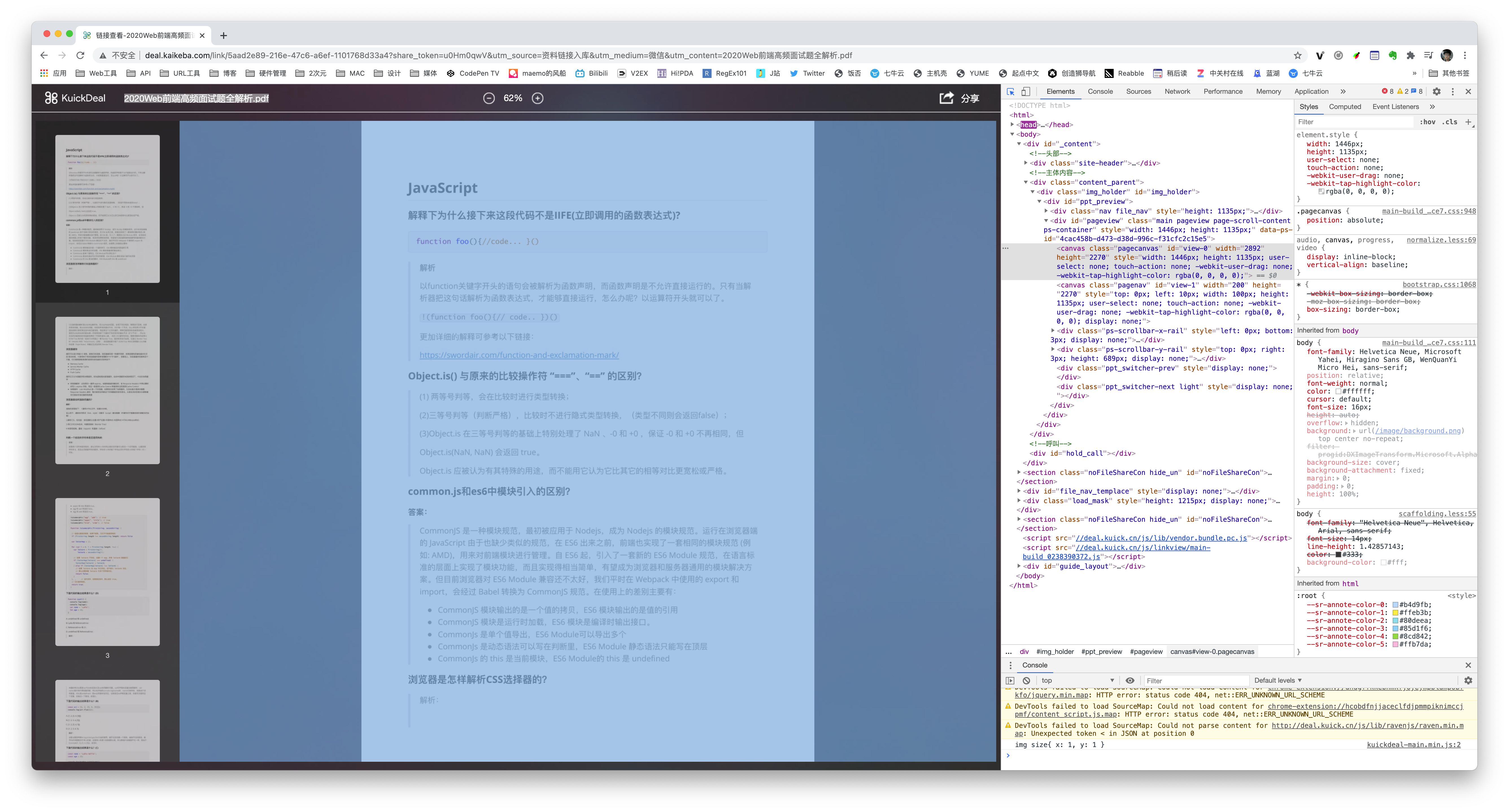
但是他的预览图却在裸奔,直接暴露了原图URL。
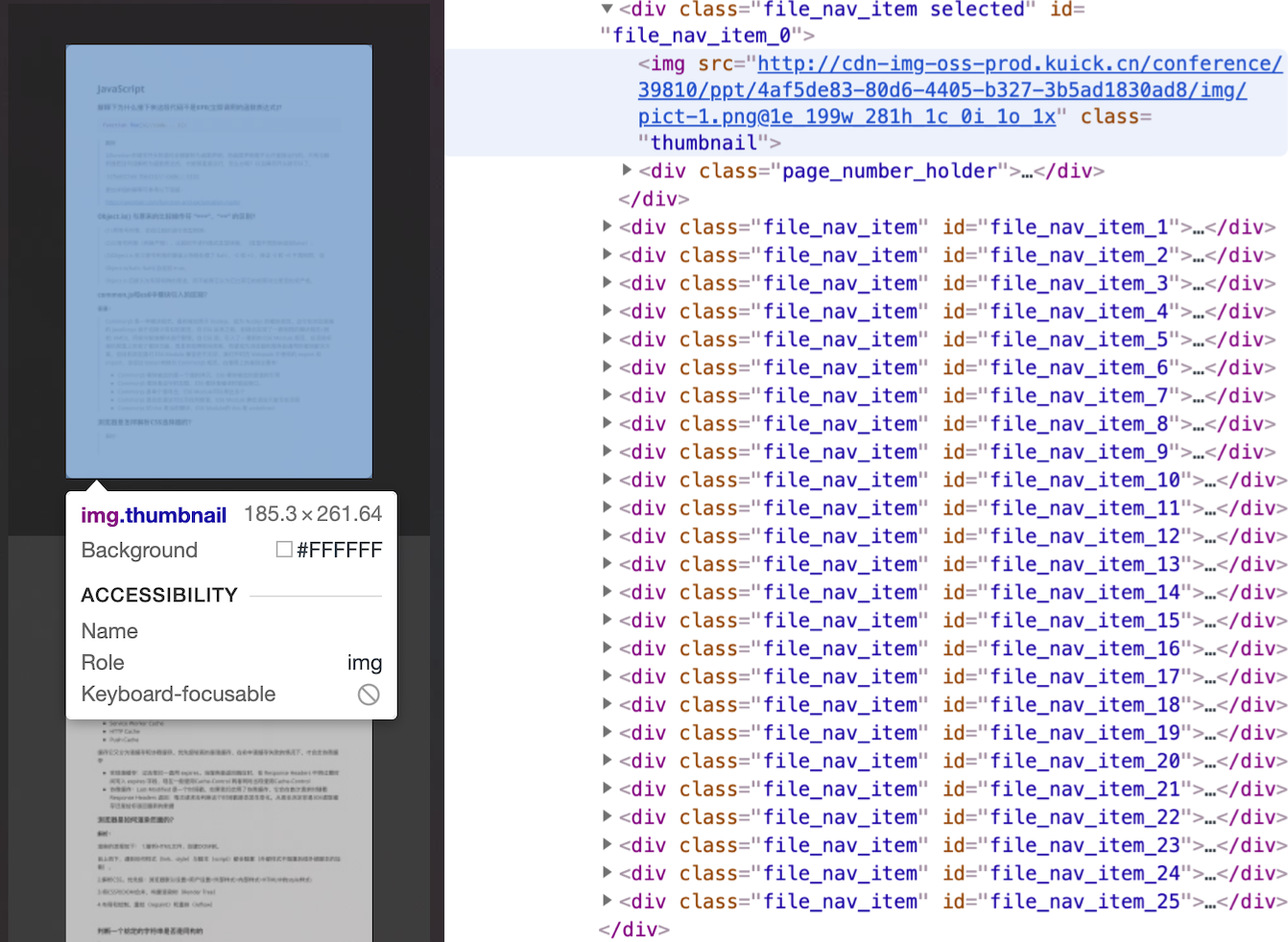
http://cdn-img-oss-prod.kuick.cn/conference/39810/ppt/4af5de83-80d6-4405-b327-3b5ad1830ad8/img/pict-1.png@1e_199w_281h_1c_0i_1o_1x稍微观察一下,还是在图片后面加了一个后缀,简单的处理了一下尺寸。
我们还是把.png后面的内容删掉。
http://cdn-img-oss-prod.kuick.cn/conference/39810/ppt/4af5de83-80d6-4405-b327-3b5ad1830ad8/img/pict-1.png这个就是正常的图片链接了,点开看了看,清晰度非常好。
可是PDF这么多页,还得手动一张一张扒?
能偷懒吗?
能。
再观察一下,其实所有26页PDF的图片,都是存在相同的目录下,而且文件名也有规律,就是按照数字排序的。
这他妈就好办了,我们直接写一个脚本,全都下载下来就行了。
脚本只需要会用mkdir、cd、wget等基本指令就能理解,里面唯一涉及到编程的东西就是用了一个for循环:使用$variable_name来表示变量。
!/bin/bash
cd /Users/lijiahui/Downloads; #这地方写的是我本人的文件目录
mkdir target;
cd ./target;
for varible1 in {1..26}
do
wget http://cdn-img-oss-prod.kuick.cn/conference/39810/ppt/4af5de83-80d6-4405-b327-3b5ad1830ad8/img/pict-$varible1.png;
done保存成文件名.sh,然后chmod +x赋予执行权限,执行它即可。
完事儿之后,把所有的图片选中,右键菜单中选择:创建PDF,即可。
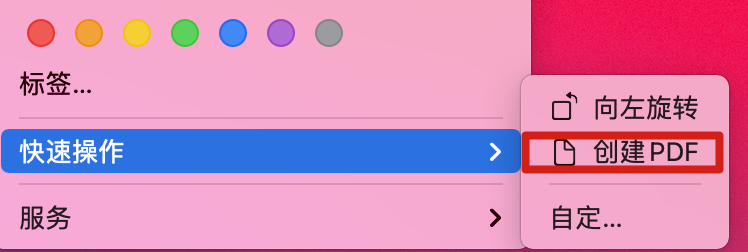
完美。
本文由 maemolee 创作,采用 知识共享署名4.0 国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Sep 8, 2020 at 03:15 pm
来看大佬操作~~~
嘿嘿,都是些基本操作,跟大佬有差距